单块gpu也能训练百亿参数大模型?
什么?单块GPU也能训练大模型了?
还是20系就能拿下的那种???
没开玩笑 , 事实已经摆在眼前:
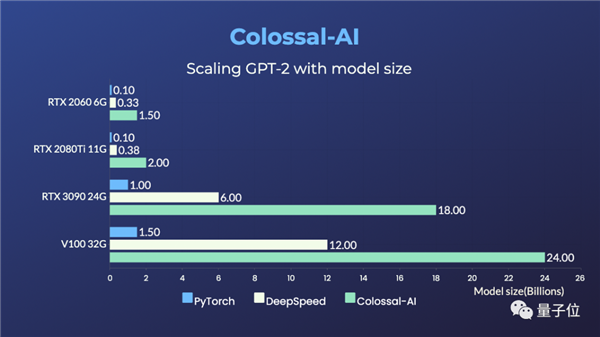
RTX20606GB普通游戏本能训练15亿参数模型;
RTX309024GB主机直接单挑180亿参数大模型;
TeslaV10032GB连240亿参数都能拿下 。
文章图片
文章图片
相比于PyTorch和业界主流的DeepSpeed方法 , 提升参数容量能达到10多倍 。
而且这种方法完全开源 , 只需要几行代码就能搞定 , 修改量也非常少 。

文章图片
文章图片
这波操作真是直接腰斩大模型训练门槛啊 , 老黄岂不是要血亏 。

文章图片
文章图片
那么 , 搞出如此大名堂的是何方大佬呢?
它就是国产开源项目Colossal-AI 。
自开源以来 , 曾多次霸榜GitHub热门第一 。
文章图片
文章图片
△开源地址:https://github.com/hpcaitech/ColossalAI
主要做的事情就是加速各种大模型训练 , GPT-2、GPT-3、ViT、BERT等模型都能搞定 。
比如能半小时左右预训练一遍ViT-Base/32 , 2天训完15亿参数GPT模型、5天训完83亿参数GPT模型 。
同时还能省GPU 。
比如训练GPT-3时使用的GPU资源 , 可以只是英伟达Megatron-LM的一半 。
那么这一回 , 它又是如何让单块GPU训练百亿参数大模型的呢?
我们深扒了一下原理~
高效利用GPU+CPU异构内存
为什么单张消费级显卡很难训练AI大模型?
显存有限 , 是最大的困难 。
当今大模型风头正盛、效果又好 , 谁不想上手感受一把?
但动不动就“CUDAoutofmemory” , 着实让人遭不住 。

文章图片
文章图片
目前 , 业界主流方法是微软DeepSpeed提出的ZeRO(ZeroReduencyOptimizer) 。
它的主要原理是将模型切分 , 把模型内存平均分配到单个GPU上 。
【单块gpu也能训练百亿参数大模型?】数据并行度越高 , GPU上的内存消耗越低 。
这种方法在CPU和GPU内存之间仅使用静态划分模型数据 , 而且内存布局针对不同的训练配置也是恒定的 。
由此会导致两方面问题 。
第一 , 当GPU或CPU内存不足以满足相应模型数据要求时 , 即使还有其他设备上有内存可用 , 系统还是会崩溃 。
第二 , 细粒度的张量在不同内存空间传输时 , 通信效率会很低;当可以将模型数据提前放置到目标计算设备上时 , CPU-GPU的通信量又是不必要的 。
目前已经出现了不少DeepSpeed的魔改版本 , 提出使用电脑硬盘来动态存储模型 , 但是硬盘的读写速度明显低于内存和显存 , 训练速度依旧会被拖慢 。

文章图片
文章图片
针对这些问题 , Colossal-AI采用的解决思路是高效利用GPU+CPU的异构内存 。
具体来看 , 是利用深度学习网络训练过程中不断迭代的特性 , 按照迭代次数将整个训练过程分为预热和正式两个阶段 。
预热阶段 , 监测采集到非模型数据内存信息;
正式阶段 , 根据采集到的信息 , 预留出下一个算子在计算设备上所需的峰值内存 , 移动出一些GPU模型张量到CPU内存 。
- 研究人员基于这一机制设计,关闭iphone时也能运行
- AMD第一款超级APU惊曝!Zen4搭档全新GPU
- 真开源了!NVIDIA发布Linux GPU驱动源代码
- intel发布全新数据中心gpu显卡,支持多种类型的各种工作
- 全球芯片危机结束在即?
- 四连击!AMD主动曝光下代GPU架构:APU史诗级变脸
- 税控盘不在身边?登录电子税务局也能查看开票信息哦
- 百万年薪、应届生也能投,这个“天才岗位”有啥要求?
- 有了这个,就算地面站全毁掉,北斗卫星也能知道自己在哪儿
- 印度高管立功 Intel:终于知道AMD/NV之外的GPU