单块gpu也能训练百亿参数大模型?( 二 )
大概逻辑如下所示:
文章图片
文章图片
这里稍微展开说明下 , 模型数据由参数、梯度和优化器状态组成 , 它们的足迹和模型结构定义有关 。
非模型数据由operator生成的中间张量组成 , 会根据训练任务的配置(如批次大小)动态变化 。
它俩常干的事呢 , 就是抢GPU显存 。

文章图片
文章图片
所以 , 就需要在GPU显存不够时CPU能来帮忙 , 与此同时还要避免其他情况下内存浪费 。
Colossal-AI高效利用GPU+CPU的异构内存 , 就是这样的逻辑 。
而以上过程中 , 获取非模型数据的内存使用量其实非常难 。
因为非模型数据的生存周期并不归用户管理 , 现有的深度学习框架没有暴露非模型数据的追踪接口给用户 。其次 , CUDAcontext等非框架开销也需要统计 。
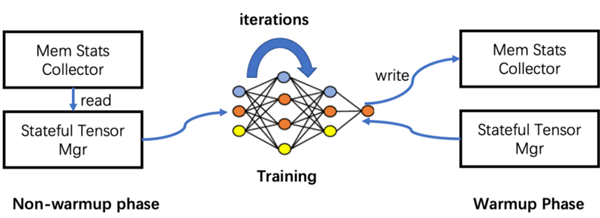
在这里Colossal-AI的解决思路是 , 在预热阶段用采样的方式 , 获得非模型数据对CPU和GPU的内存的使用情况 。
简单来说 , 这是道加减法运算:
非数据模型使用=两个统计时刻之间系统最大内存使用—模型数据内存使用
已知 , 模型数据内存使用可以通过查询管理器得知 。
具体来看就是下面酱婶的:

文章图片
文章图片
所有模型数据张量交给内存管理器管理 , 每个张量标记一个状态信息 , 包括HOLD、COMPUTE、FREE等 。
然后 , 根据动态查询到的内存使用情况 , 不断动态转换张量状态、调整张量位置 , 更高效利用GPU显存和CPU内存 。
在硬件非常有限的情况下 , 最大化模型容量和平衡训练速度 。这对于AI普及化、低成本微调大模型下游任务等 , 都具有深远意义 。
而且最最最关键的是——加内存条可比买高端显卡划算多了 。

文章图片
文章图片
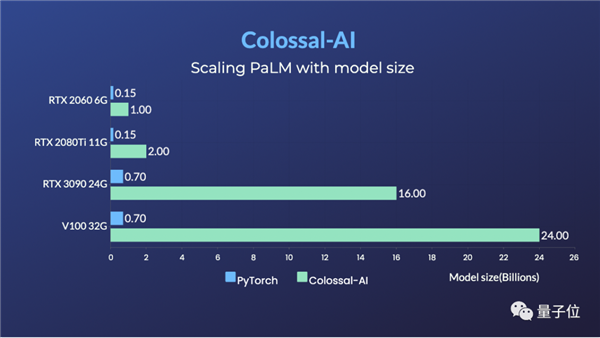
前不久 , Colossal-AI还成功复现了谷歌的最新研究成果PaLM(PathwaysLanguageModel) , 表现同样非常奈斯 , 而微软DeepSpeed目前还不支持PaLM模型 。
文章图片
文章图片
Colossal-AI还能做什么?
前面也提到 , Colossal-AI能挑战的任务非常多 , 比如加速训练、节省GPU资源 。
那么它是如何做到的呢?
简单来说 , Colossal-AI就是一个整合了多种并行方法的系统 , 提供的功能包括多维并行、大规模优化器、自适应任务调度、消除冗余内存等 。

文章图片
文章图片
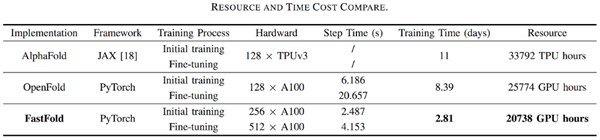
目前 , 基于Colossal-AI的加速方案FastFold , 能够将蛋白质结构预测模型AlphaFold的训练时间 , 从原本的11天 , 减少到只需67小时 。
而且总成本更低 , 在长序列推理任务中 , 也能实现9~11.6倍的速度提升 。
这一方案成功超越谷歌和哥伦比亚大学的方法 。
文章图片
文章图片
此外 , Colossal-AI还能只用一半GPU数量训练GPT-3 。
相比英伟达方案 , Colossal-AI仅需一半的计算资源 , 即可启动训练;若使用相同计算资源 , 则能提速11% , 可降低GPT-3训练成本超百万美元 。
- 研究人员基于这一机制设计,关闭iphone时也能运行
- AMD第一款超级APU惊曝!Zen4搭档全新GPU
- 真开源了!NVIDIA发布Linux GPU驱动源代码
- intel发布全新数据中心gpu显卡,支持多种类型的各种工作
- 全球芯片危机结束在即?
- 四连击!AMD主动曝光下代GPU架构:APU史诗级变脸
- 税控盘不在身边?登录电子税务局也能查看开票信息哦
- 百万年薪、应届生也能投,这个“天才岗位”有啥要求?
- 有了这个,就算地面站全毁掉,北斗卫星也能知道自己在哪儿
- 印度高管立功 Intel:终于知道AMD/NV之外的GPU