databricks:一个给数据工程师的平台
在数据库领域 , 如果问当下谁最火 , 那Databricks一定排得上号 。
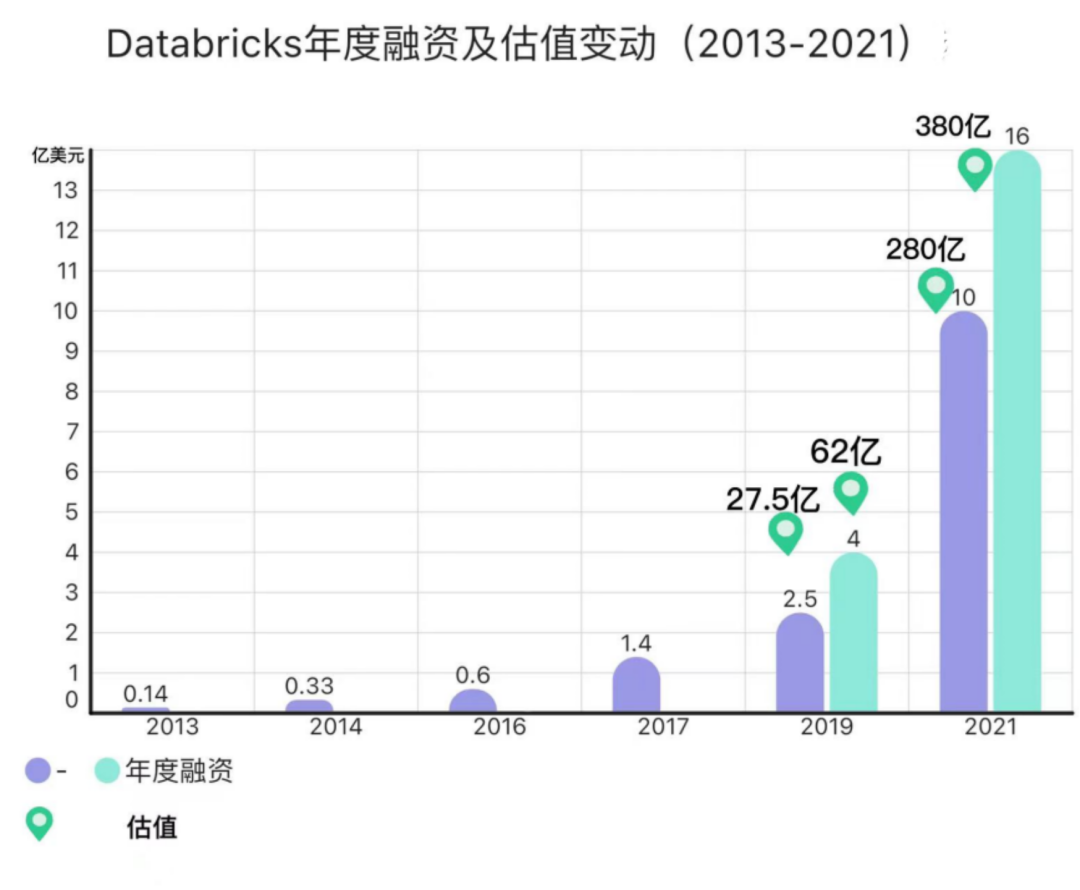
去年8月 , 距离10亿美元的G轮融资刚过去7个月 , Databricks再次获得16亿美元H轮融资 , 身价摇身一变成380亿美元 , 成为外界一致认为的超级独角兽 。一直以来 , 数据领域备受关注 , 如果从2007年开始计算 , 全球的数据量至今已经膨胀了近200倍 , 数字化被写入战略规划成了各类行业的共识 。
在数据量井喷的背景下 , 上云趋势也越来越明确 , 以Snowflake、Databricks为代表的大数据公司应运而生 , 前者基于AmazonS3打造了云端的数据仓库 , 后者除了推出Lakehouse(湖仓一体) , 现在又押宝机器学习 , 试图包管数据在抵达机器学习之前的所有流程 。
不同的是 , Databricks已经从原来的infra向更广泛场景延伸 , 和昔日的伙伴Snowflake同台竞技 。与此同时 , 以AWS为代表的云巨头 , 也都曾战略性投资过Databricks , 但现在也都在自研数据分析套件 , 竞合关系渐趋白热化 , 让数据基础设施的战火扑朔迷离 。
01从0到1
企业的性格往往被它的创始人和技术背景所决定 。
十几年前在UCBerkley的AI实验室里 , Ghodsi和伙伴发起Spark项目:做一个能够更轻松处理大量数据和机器算法的引擎 , 并且开源了代码 。相比较多数开源项目 , 面向的都是底层技术性强要求的infra工程师 , spark面向更广泛的客户群 , 同时在上层加了很多的新的API , 降低了技术门槛 。
因为没有优秀的开发者社区运营和推广团队 , Spark变现比较难 , 之后团队成员决定成立Databricks , 以商业化方式推动Spark社区发展 。即便Spark是过去硅谷的顶流产品 , 但这并没有让AWS等巨头买账 , 他们选择绕过Databricks , 直接将Spark集成到自己的产品里 。在Databricks卖产品还不如办Spark峰会收入高的时候 , AmazonEMR已经针对Spark实现了几亿营收 。
Databricks创始团队走了一条不被大众熟知的激进的路:云 。
虽然不管对公司还是客户来说 , 云可以更快部署 , 也更容易维护 , 但正如联合创始人ReynoldXin所说 , 大部分的人知道云是未来 , 但绝不是现在 。当时只有小部分风投注资这家初创企业 , NewEnterpriseAssociates的投资者PeteSonsini说:“我们在Databricks的软件收入为零时投资 , 认为他们会在大流行中加速发展 , 也许是一两个月 , 每个人都无法及时知道会发生什么” 。和Databricks一样 , 他们也在赌未来 。
文章图片
文章图片
图:Databricks年度融资及估值变动
2013到2015这三年 , 虽然有硅谷风投支持 , Databricks也借力这些资金吸引人才 , 推出了基于云端的简化大数据处理平台DatabricksCloud , 但不管是招主管、找融资还是见客户 , Databricks都会被质疑:真的不支持on-prem吗?
因为背靠Spark , 很多客户甚至愿意年付几千万美金让Databricks提供咨询定制化项目 , 但Databricks做的是一个给数据工程师的平台,这是当时大部分公司闻所未闻的玩法,也是前几年商途不顺的原因之一 。值得一提的是 , 彼时的云界开源前辈Cloudera曾改名“CloudEra” , 可在当时的市场情况下 , 最终还是转向了on-prem做定制和售后支持才得以存活 。
在这种逻辑下 , 云厂商把开源软件拿来经过简单的封装 , 再作为服务卖出去 。由于这个过程只需要简单的部署和调试 , 工程成本极低 , 定价也不高 , 巨头从中赚走了大部分 , 这对Databricks来说相当于吸血 , 怎样和有钱有人的云巨头对抗 , 是Databricks亟需在技术上打造的壁垒 。
- twitter正在测试一个新的\“cc\”按钮
- 年轻人的第一个读书网站?近亿人在B站看读书类视频
- 苹果商店将下架长期不更新应用程序,并给开发者30天的时间进行更新
- 【十年@每一个奋斗的你】安徽黄山古稀徽商40年立足桑梓“拥抱世界”
- 智慧经营系统给数字门店带来的优势有哪些?
- 抖音嘉年华多少钱(一个嘉年华主播能得多少钱?)
- 世界地球日,他们邀用户给地球写“三行诗”表白
- 王者荣耀|《王者荣耀》又双叕曝抄袭风波,又要甩锅给外包()
- 金铲铲之战阴森的森林里出现一个洞洞里有什么(相知执手天涯阴森的森林答案)
- 腾讯会议怎么把主持人给别人(腾讯会议转让主持人身份步骤解析)