英伟达联合ibm打造“大加速器内存”
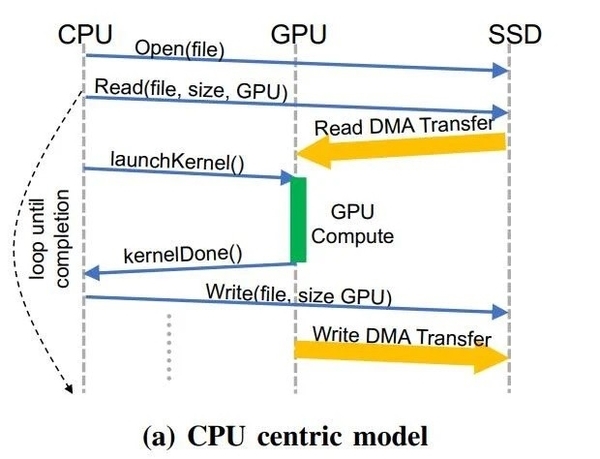
传统的数据读取依赖于CPU执行虚拟地址转换、基于页面的按需数据加载以及其它针对内存和外存的大量数据管理工作 , 作为电脑核心部件之一的显卡是无法直接从SSD中读取数据 。
但随着人工智能和云计算的兴起 , 有GPU直接读取SSD硬件内数据 , 是最高效的方式 。
文章图片
文章图片
为了让GPU应用程序能够直接读取数据 , 英伟达联合IBM , 通过与几所大学的合作打造一套新架构 , 为大量数据存储提供快速“细粒度访问” , 也就是所谓的“大加速器内存”(BigAcceleratorMemory , 简称BaM) 。
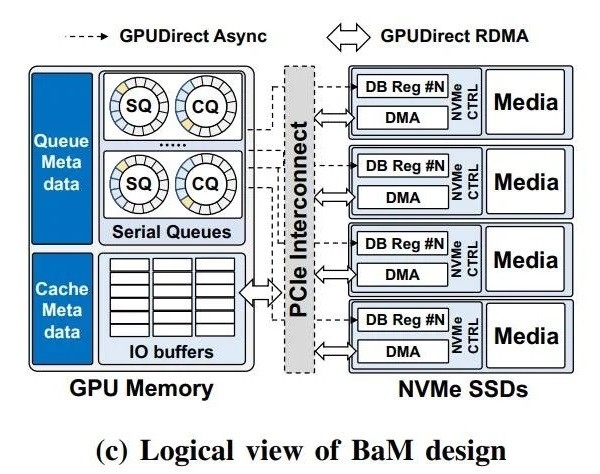
通过这一技术 , 能够提升GPU显存容量、有效提升存储访问带宽 , 同时为GPU线程提供高级抽象层 , 以便轻松按需、细粒度地访问扩展内存层次中的海量数据结构 。
文章图片
文章图片
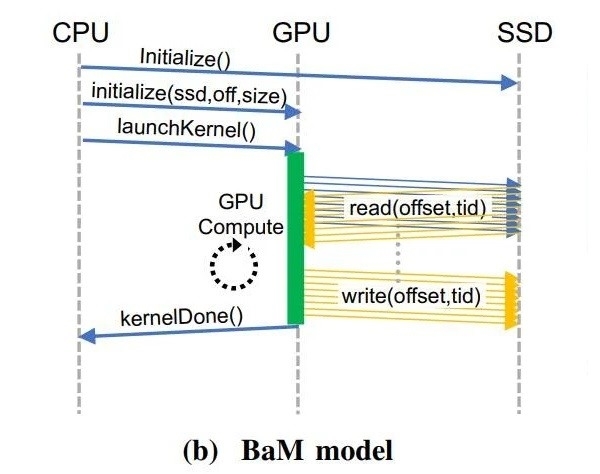
对于普通用户来说 , BaM拥有两大优势 , 第一是基于软件管理的GPU缓存 , 数据存储和显卡间的信息传输分配 , 都交给GPU核心上的线程来管理 。
并通过使用RDMA、PCIExpress接口以及自定义的Linux内核驱动程序 , BaM允许GPU直接打通SSD数据读写 。
第二就是打通NVMeSSD的数据通信请求 , BaM只会在特定数据不在软件管理的缓存区域时 , 才让GPU线程做好参考执行驱动程序命令的准备 。在图形处理器上运行繁重工作负载的算法 , 能够通过针对特定数据的访问例程优化 , 从而实现针对重要信息的高效访问 。
在以CPU为中心的策略电脑中 , 会因为CPU、GPU之间的数据传输以及I/O流量的放大 , 拖累具有细粒度的数据相关访问模式 。
研究人员在BaM模型的GPU内存中 , 提供基于高并发NVMe的提交/完成队列的用户级库 , 使未从软件缓存中丢失的GPU线程 , 能够以高吞吐量的方式来高效访问存储 。
更重要的是 , BaM方案在每次存储访问时的软件开销极低 , 并支持高度并发的线程 。在基于BaM设计+标准GPU+NVMeSSD的Linux原型测试平台的相关实验测试中 , BaM交出相当喜人的成绩 。
作为代替基于CPU统管一切事务的解决方案 , BaM的研究表明 , 存储访问可同时工作、消除同步限制 , 并且明显提升I/O带宽效率 , 让应用程序的性能获得大幅提升 。
NVIDIA首席科学家BillDally指出:得益于软件缓存 , BaM不依赖于虚拟内存地址转换 , 天生就免疫TLB未命中等序列化事件 。
文章图片
文章图片
【英伟达联合ibm打造“大加速器内存”】编辑点评:随着ResizableBAR和SAM技术的发展和应用 , GPU和CPU之间的带宽瓶颈得到极大的缓解 , 但相比于从CPU获取数据 , 让GPU直接从SSD中获得数据的应用效率会更高 。
虽然新的BaM目前尚未明确如何在消费者领域应用 , 但相信不久后也会有相关产品面世 。

文章图片
文章图片
责任编辑:振亭文章纠错
话题标签:CPU处理器显卡CPU
- 我国固定宽带接入用户总数达5.45亿户
- 专门“看”天色 自贡首部X波段天气雷达项目获批
- 英伟达宣布自动驾驶芯片orin正式投产销售
- 英伟达发布新款nvidiartx笔记本电脑gpu
- 英特尔或将推出新一代ai处理器对标英伟达
- 英伟达发144核Grace CPU超级芯片:数据中心专属
- 英伟达推出第四代nvidiadgx系统,全球首个ai平台
- 北京量子院联合业界推出“天工经世”,将量子计算应用于金融业
- 2021都市打工人睡眠报告: 仅30.6%打工人时间达标
- 小米美团闪购合作官宣 手机智能硬件产品最快30分钟送达